July 30, 2020 by Siobhan Climer and Mike Czerniak
For 27 minutes on the afternoon of Friday, July 17th it seemed the modern world was in ruins.
Sometime around 4:15 pm Central Time, websites across the globe stopped responding. Creatives’ Patreon accounts shut down; developers’ late Friday afternoon projects came to a standstill with Gitlab; even gamers on Discord heard only silence from their compatriots.
Initial reports suspected a cyber attack; this leap made sense given it immediately followed the scandalous Twitter hack and an “emergency directive order” from the Department of Homeland Security in response to a critical Windows Server worm.
It was not a cyber attack; major cloud platform provider Cloudflare quickly reported the outage was a result of a simple, but costly, typo.
Internet Downtime Result Of Cloudflare Configuration Error
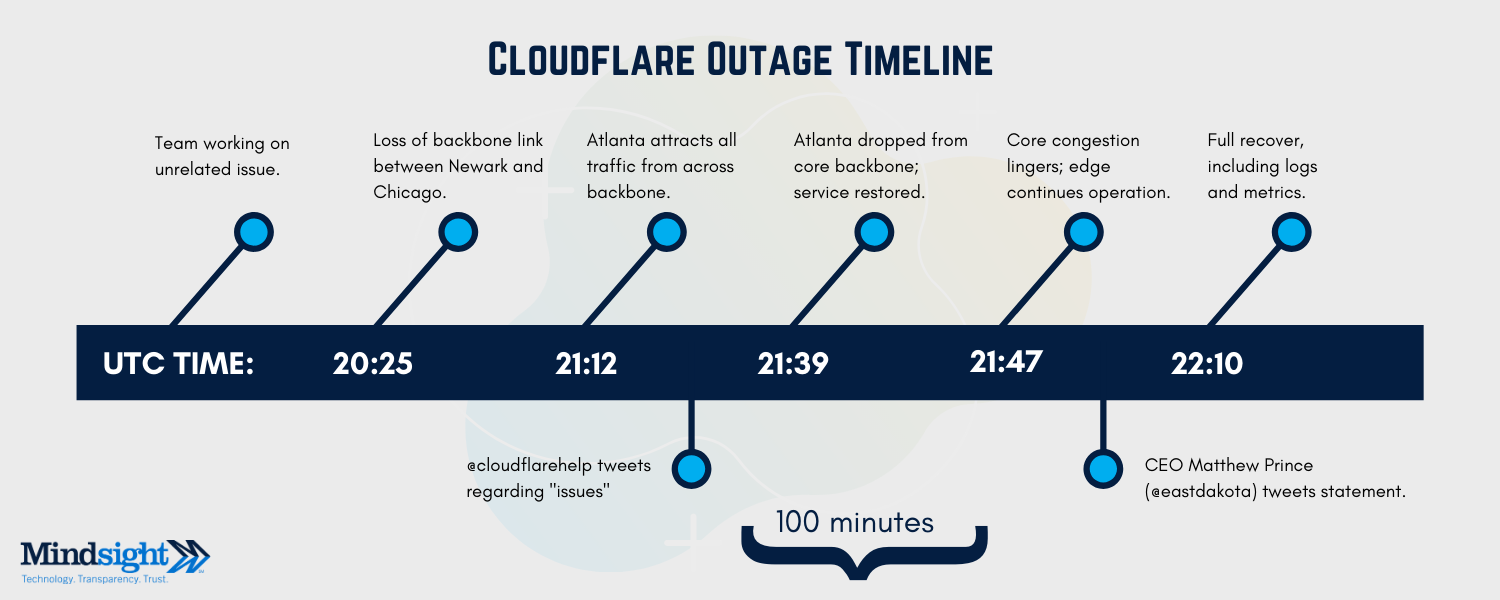
Cloudflare’s Chief Technology Officer, John Graham-Cumming, published a forthright statement on the company’s blog explaining the network engineering team, in unrelated work, updated the configuration on an Atlanta router. The configuration contained an error rerouting all traffic through Atlanta, overwhelming the router and causing the Cloudflare outage.
While the statement led many to breathe a sigh of relief – and some to shed compliments on Cloudflare’s transparency – it almost leaves us with more questions.
Questions about everything, from the risks of a centralized internet to the tentative nature of the fundamental elements of society and information-sharing critical to work, life, and communications – especially during a pandemic.

How Did The Cloudflare Outage Cause Worldwide Downtime?
Cloudflare launched its DNS (Domain Name System) service in late 2018. A DNS helps connect domains to their IP addresses. The Cloudflare outage was notable for many reasons. It highlighted the global interconnectedness (affected locations ranged from Chicago to Curitiba) and potential overreliance on a single DNS provider.
Yet, it also showcased how smart network architecture matters. Due to the Cloudflare backbone, a series of private lines between its global data centers that enables faster, more reliable traffic pathways, only about 50% of traffic was impacted.
While 50% of a lot is still, well, a lot, this structure ensured some communications could continue to operate without disruption.
“Because of the architecture of our backbone this outage didn’t affect the entire Cloudflare network and was localized to certain geographies,” says Graham-Cummings in the Cloudflare statement.
Lessons Learned From The Cloudflare Outage
Cloudflare outlined their next steps in their statement:
“Introduce a maximum-prefix limit on our backbone BGP sessions – this would have shut down the backbone in Atlanta, but our network is built to function properly without a backbone. This change will be deployed on Monday, July 20.
“Change the BGP local-preference for local server routes. This change will prevent a single location from attracting other locations’ traffic in a similar manner. This change has been deployed following the incident.”
For businesses and cloud computing service providers, the next steps are less clear.
In a lengthy, technical discussion of the Cloudflare outage on Hacker News, CIOs, CISOs, CTOs, SVPs of DevOps, and others laid out plans for diversifying name servers, rerouting traffic via CDN, enacting more frequent “Chaos Monkey” disaster recovery drills, improved resiliency, and a million other actionable steps.
One comment, by a Twitch engineer, caught our eye:
“Networking in general is a far less sophisticated world than we might like to hope. You have to deal with quirks of vendor-specific firmware, creaky protocols, and so on, and the culture of networking has been a bit behind some other areas of software in embracing testing.”

Improving Resiliency Of Your Cloud Infrastructure
While you aren’t going to be able to solve the internet today, there are steps you can take to improve the resilience of your on-premise and cloud-based infrastructure.
Step 1: Assess – Start with an understanding of your current on-premise and hybrid infrastructure.
Step 2: Plan – Make a plan to migrate or manage infrastructure with resilience in mind.
Step 3: Implement – Enact that plan with certified AWS and Azure experts on your team.
Step 4: Optimize – Improve the environment for ideal performance, accessibility, and cost management.

Should We Expect Another Cloudflare Outage?
Probably. It might not be Cloudflare, but DNS outages will continue. The Twitch user above pointed out an uncomfortable truth about networking today, also alluded to by Graham-Cumming in the Cloudflare outage stagement.
This was a typo.
This truth begs the question: what kind of process enables a single typo to take down swaths of the internet?
As the head of DevOps at a major financial exchange noted, it’s time for IT leaders to “just be ready”.
See what we can do for you. Contact us today.
Like what you read?
About Mindsight
Mindsight is industry recognized for delivering secure IT solutions and thought leadership that address your infrastructure and communications needs. Our engineers are expert level only – and they’re known as the most respected and valued engineering team based in Chicago, serving emerging to enterprise organizations around the globe. That’s why clients trust Mindsight as an extension of their IT team.
Visit us at http://www.gomindsight.com.
About The Authors
Mike Czerniak is the Vice President of Project Services At Mindsight, an IT Services and Consulting firm located in the Chicago area. With 20 years of experience in information technology and the cloud, Mike has helped hundreds of organizations with architecting, implementing, and deploying cloud solutions. For the last 5 years, Mike has focused on providing Mindsight’s customers with guidance in approaching – and managing – the cloud. Mike is AWS, Microsoft Azure, VMware certified, and remains deeply invested in providing an agnostic, consultative voice for organizations on their cloud journey. In his free time, Mike enjoys biking with his 9-year old son, recently completing a 50-mile bike ride!
Siobhan Climer writes about technology trends in education, healthcare, and business. With over a decade of experience communicating complex concepts around everything from cybersecurity to neuroscience, Siobhan is an expert at breaking down technical and scientific principles so that everyone takes away valuable insights. When she’s not writing tech, she’s reading and writing fantasy, hiking, and exploring the world with her twin daughters. Find her on twitter @techtalksio.
How To Tackle Cybersecurity In A Remote Work Environment: A Cybersecurity Report
